
Optimizing Dynamic-Shape Neural Networks on Accelerators via On-the-Fly Micro-Kernel Polymerization
(基于微核聚合的加速器动态形状神经网络优化)
一、涉及到的定义
1.计算图
计算图是神经网络中的一组算子及其数据依赖关系的表示,用于描述神经网络的前向和反向传播过程
(1)计算图的类型:
静态计算图
在执行前先构建完整的计算图,然后通过给定的输入数据反复执行,计算图一旦定义,不能在运行过程中修改。
提前构建计算图后可以进行优化,如内存优化、操作融合等,能提高执行效率。适合推理阶段的高效执行
动态计算图
在执行过程中动态构建计算图,每次前向传播时计算图都会重新生成,因此可以根据具体的输入动态调整网络结构
相比静态图,动态图在某些场景下的性能优化空间较小,特别是在推理阶段,性能可能略逊,原因如图下:
- 由于静态图的计算图在运行前就已经完整定义,因而框架可以从全局视角对图进行分析和优化,包括使用数据流分析、并行化处理、内存分配优化等复杂的优化操作
- 由于动态图需要在每次在还行模型时动态生成,因而在优化时无法站在全局的视角,只能逐步构建,违法进行跨层操作融合
- 动态图可以处理更加灵活的控制流结构(如 if 语句),但是因此也会带来额外的计算开销
(2)为什么可以动态构建计算图?
操作即构建:
在 PyTorch 等框架中,计算图是在执行过程中通过每一步的操作动态构建的。例如,当你定义一个线性层操作或卷积层时,并不会立即创建整个计算图,而是在输入数据真正传递到该层时,框架会即时构建与这一操作相关的计算节点。
计算图依赖于输入数据:
动态图的计算不仅依赖于模型的结构,还依赖于输入数据的形状和内容。例如,递归神经网络(RNN)等网络在处理不定长的输入时,每次执行前向传播可能需要生成不同的计算图。
执行与定义合二为一:
在动态图框架中,计算图的定义与执行是一体的。每当执行一个操作,框架就在内部即时创建对应的计算图节点,并执行该操作。因此,计算图并不是预先定义好的,而是随代码的执行动态生成和处理。
控制流:
在动态图中,你可以使用 Python 中的控制流结构(如
if语句或for循环)来动态改变网络的行为。因此,计算图并不是在模型定义时完全固定的,而是可以根据输入和条件语句在运行时动态调整。
2.循环平铺结构
将大循环分解成小块,使得每块的数据能够有效地放入CPU缓存中,减少对主存的访问次数 有助于提高局部性,因为缓存比主存的访问速度更快
例子:
1 |
|
应用循环平铺的版本:
1 |
|
二、论文全文内容总结
1 Introduction
三种张量计算的代表性方法
该部分首先介绍了现有的三类支持高性能张量计算的代表性方法:
- 供应商提供的自建库
| 硬件平台 | x86 CPUs | Nvidia GPUs |
|---|---|---|
| 自建库 | oneDNN | cuBLAS |
上述自建库的实际实验效果有限,因为自建库针对特定形状进行优化的操作符实现并不适应所有形状,因而不可避免地导致性能下降。
比如如下所示使用在cuBLAS实现的GEMM例程对于不同的张量形状有显著的性能差异:
| 张量形状(M,N,K) | (4096,4096,4096) | (105,1024,12544) |
|---|---|---|
| 计算能力 | 262.2 TFLOPS | 22.3 TFLOPS |
- 静态形状算子的张量编译器
大多数张量编译器,如TensorFlow XLA [29],TVM [7]和TC [55],通过在大量搜索空间内搜索循环平铺结构来优化张量运算符,以确定给定形状的最佳实现。尽管如此,这些自动编译器在编译期间需要操作者的形状的先验知识。由于广泛搜索空间内的搜索成本很高,这种限制使得在动态场景中跨所有潜在形状优化张量运算符变得不可行。
- 动态形状算子的张量编译器
最近,一些研究探索了动态形状编译器[49,65,70]。一个例子是DietCode [65],它通过优化形状通用搜索空间来增强传统的自动搜索器,以实现最佳操作符。然而,这些动态形状自动生成器仍然依赖于预定义的形状描述和离线代码优化。
现有方法弊端和解决方案
接下来对现有的方法的弊端进行阐述,并给出MIKPOLY的解决方案:
现有的方法的弊端:利用了处理一系列形状的自动化程序来离线生成优化程序的有限子集。然而,这些自动排序器不能保证对预定义范围之外的形状的有效甚至正确执行,从而限制了它们在具有频繁形状变化的动态场景中的可用性。
MIKPOLY的解决方案:创建一组微调的固定大小的微内核,每个微内核代表一个平铺的循环嵌套,负责执行张量运算符的一部分。这些微内核是离线生成的,并动态组合,为模型执行期间遇到的任何张量形状生成优化的代码。关键的挑战在于确定一个有效的组合策略,并在模型执行过程中以非常低的成本生成优化的代码。
本文所做的工作
根据该解决方案,文章阐述了本文所做的工作:
- 提出了一个两阶段的方法来生成一个优化的张量程序
- 引入了一个精确而轻量级的成本模型,有利于高效的在线聚合
- 在代表性的两个加速器——GPU和NPU上进行测试,效果很好
2 Background and Motivation
背景:现实世界的应用程序通常表现出动态行为,例如语言建模中不同长度的句子,使得静态形状的神经网络不足。为了解决这一限制,动态形状神经网络已经被提出来支持更复杂的现实世界的智能应用。代表性场景如下:
- 动态批次大小:较大批次会加快参数收敛的速度,并提高模型的稳定性。当前研究者提出动态批次大小的方法,随着训练过程动态调整批次大小,以提升性能和适应真实应用场景
- 动态图像分辨率:传统的方法会将图像调整为固定尺寸,这样往往会导致信息的丢失,特别是在检测复杂场景中的小目标时。现代方法会通过引入高级池化方法,在不损失图像细节的前提下,提升测量精度。
- 动态序列长度:在自然语言处理应用中,输入序列的长度是动态变化的,通常的解决方案是将序列填充到固定的最大长度,但是这种填充策略会浪费资源,特别是实际序列长度远小于最大序列长度的时候 ,因而要求使用优化的策略来动态处理序列长度,减少资源浪费,提高计算效率
现有技术解决算子的实现
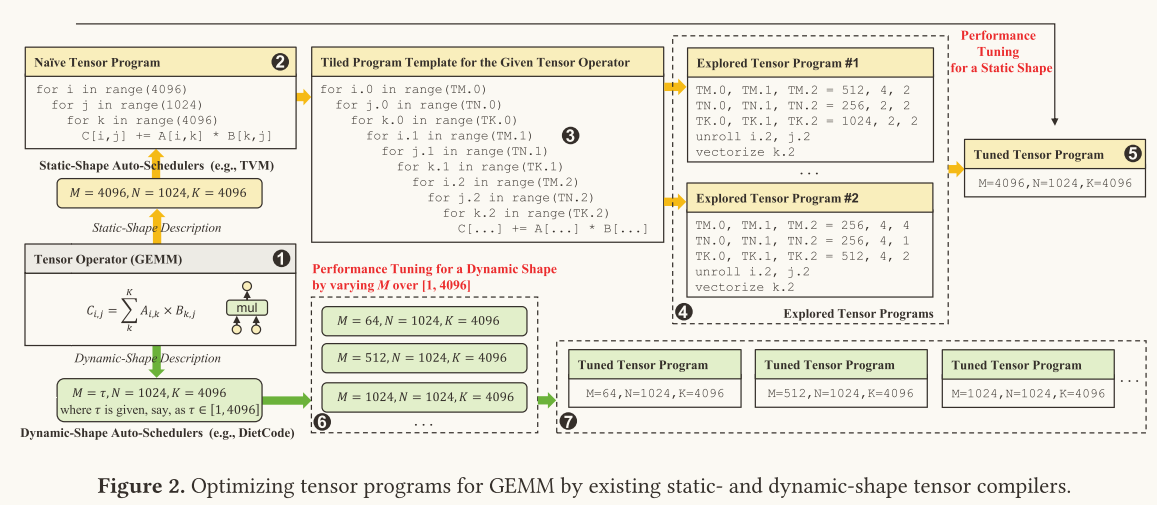


静态形状张量编译器(如TVM):
- 功能:为固定形状的张量(M N K )生成高效实现,通过枚举不同的平铺大小,找到最佳的配置,从而优化张量操作的性能
- 问题:需要大量的离线编译时间,且只适用于特定的输入形状,另外在实际的动态形状任务中效率较低
动态形状张量编译器(如DietCode):
- 功能:为不同形状生成多个预编译的张量程序,在运行时可以根据输入张量的形状进行选择,从而减少了编译开销
- 局限性:要求在编译阶段事先了解可能的张量形状范围,从而限制了其应用范围
Mikpoly解决算子的实现
(1)MikPoly 的核心思想
- MikPoly 主要目的是解决动态形状张量运算的挑战,特别是在不同形状的张量运算中保持高性能。
- 通过一个两阶段的模板流程,MikPoly 在编译阶段生成了一组高度优化的微内核,并在运行时根据动态形状选择最优的微内核来执行张量运算。
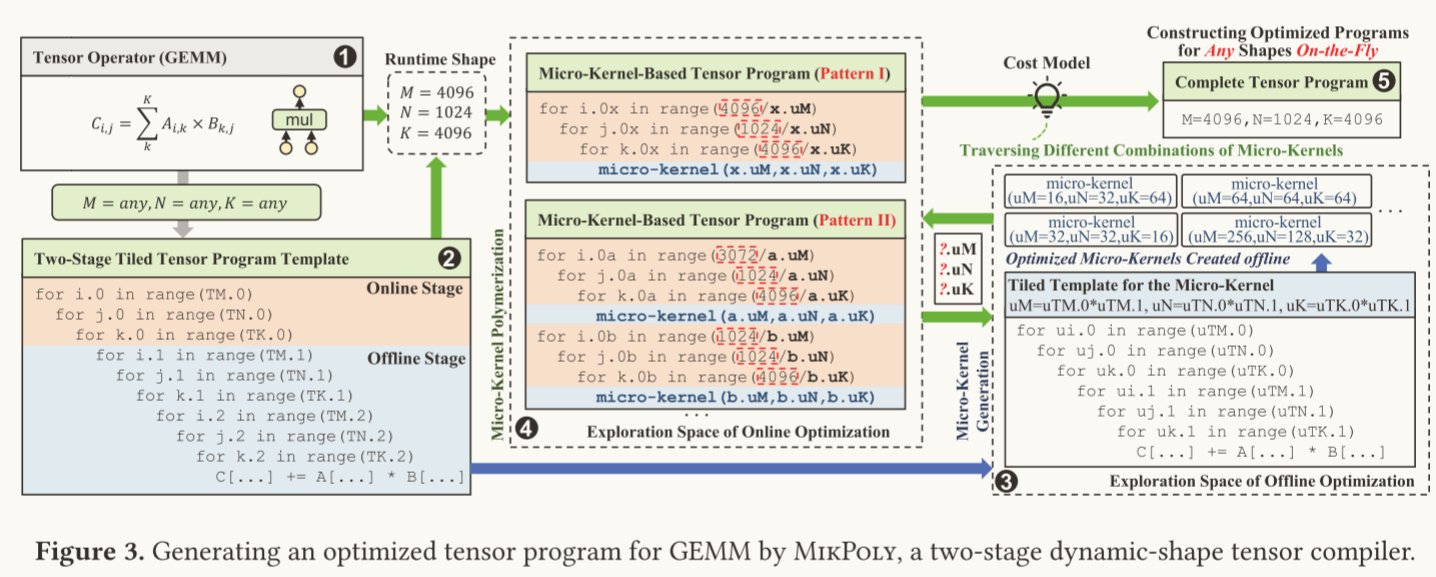
(2)两阶段流程
- 离线阶段:在编译时,MikPoly 使用静态形状(如 M=4096,N=1024,K=4096)生成一系列的固定尺寸的微内核。这些微内核是通过探索最佳的 tile 参数和循环展开优化而生成的,并针对不同形状进行优化。
- 在线阶段:在运行时,当具体的张量形状 M,N,K确定后,MikPoly 动态选择和组合这些预先优化好的微内核,生成最优的张量操作程序。在线阶段探索了不同的微内核组合策略来适应当前形状。
(3) 微内核多样化
- MikPoly 提供了灵活的微内核生成和组合策略。例如,在离线阶段生成的微内核(如 micro-kernel(a.uM, a.uN, a.uK) 和 micro-kernel(b.uM, b.uN, b.uK))被灵活地组织在一起,以应对不同的形状变化。
- Pattern I 和 Pattern II 是两种不同的微内核聚合模式,它们根据不同的形状和性能需求进行适配选择。
(4)成本模型的使用
- MikPoly 使用了一个精确且轻量化的成本模型,在运行时快速评估不同微内核组合的开销,并选择最佳组合,从而确保高效的执行。图中显示,成本模型指导了动态微内核的选择过程。
(5)最终效果
- MikPoly 通过这种基于微内核的动态形状优化,有效地提升了动态形状神经网络在现代加速器上的性能,尤其是在形状变化频繁的情况下,MikPoly 显著缩短了编译时间,并且优化了运行效率。
3 The MIKPOLY Design
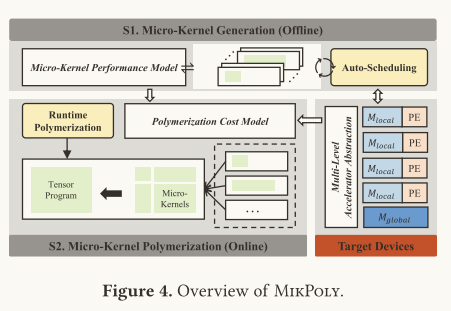
Mikpoly的两阶段设计:微内核生成 (S1) 和微内核聚合 (S2)
- S1:微内核生成(Offline):
- 在编译时(离线),MikPoly 使用模板驱动的调优流程生成微内核。
- 通过自动调度(Auto-Scheduling)来生成一组优化的微内核,每个微内核针对特定尺寸进行优化。
- 同时开发一个微内核性能模型(Micro-Kernel Performance Model),为每个微内核提供性能预测。
- S2:微内核聚合(Online):
- 在运行时,基于已知的张量形状,MikPoly 通过运行时聚合组件(Runtime Polymerization)对张量操作的程序模板进行重新组织,生成不同的实现。
- MikPoly 使用一个轻量级的聚合成本模型(Polymerization Cost Model)选择最佳的微内核组合,以最小化计算开销。
微内核生成阶段 (S1) 的工作流程:
- MikPoly 首先通过模板驱动生成微内核,并使用自动调度系统对其进行性能调优。
- 针对不同的尺寸(形状)生成一组高度优化的微内核程序。
- 该阶段的生成是离线进行的,因此不影响运行时性能。
**运行时的微内核聚合阶段 (S2)**:
- MikPoly 在已知张量形状后,通过在运行时重新组织微内核来适应动态形状。
- MikPoly 使用轻量级成本模型,动态选择最适合的微内核组合,从而为每个特定的形状找到最佳的执行方案。
- 这种方法能够在不同形状之间提供高效的切换,同时保持较低的计算开销。
多级加速器抽象:
- MikPoly 的设计采用了多级加速器抽象(Multi-Level Accelerator Abstraction),将每个计算单元抽象为处理引擎(PE, Processing Engine),并使用局部内存和全局内存来表示不同层次的内存架构。
- 这种抽象层次有助于 MikPoly 在硬件层面实现高效的资源利用,并提升神经网络的计算性能。
启发式策略探索:
- MikPoly 还探索了基于启发式的聚合策略,以根据运行时的张量形状选择最佳策略。通过多样化的策略选择,MikPoly 能够在不同的执行环境中高效运行。
最终目标:MikPoly 通过结合离线微内核生成和在线微内核聚合,解决了动态形状张量操作中性能不稳定的问题,能够在现代加速器上显著提高动态形状神经网络的执行性能。
多级加速器抽象
Mikploy为硬件平台设计了多级加速器抽象,考虑指标
一个张量程序在硬件上运行的并行性依赖于
两款代表性加速器的H指标如下图所示:

两阶段优化
该部分通过GEMM算子的动态形状优化后张量程序执行过程的例子对MIKPOLY的两阶段优化过程进行阐述。
解耦优化空间
==介绍循环平铺的概念==
将平铺程序模版定义为Q,可将Q分为两个部分:
离线优化空间
①使用
②通过模版
在线优化空间
①使用预先定义好的聚合模式(GEMM则为表3中的两种模式)为
②对得到的所有程序通过探索所有固定大小微内核的聚合策略实现参数的实例化
③在这些实例化的程序中根据成本模型选取性能最好的程序样例进行导出
优化目标
使用
这个
微内核生成
自动调整固定大小的微内核
将离线优化空间中使用一个模版
该阶段的运行过程如下:(三个超参数:
- 根据模版
生成每维度的平铺大小在 范围的微内核,将这些微内核统一包含在 中 - 生成一个张量程序,如下:
1 | for i in range(dimension_size_1): |
设置张量程序中的三个dimension_size的范围为
- 使用第一步得到的微内核集合执行这些测试程序,按照运行过程中的平均性能进行排名,保留
的性能表现者
在实际的评估结果中,我们选择
微内核性能模型
在微内核生成的过程中,Mikpoly会为每一个微内核生成一个性能模型,微内核定义为
假设GEMM表示为 (M N K) = (t1 * uM, t2 *uN, t3 * uK)
(1)
得到单个
(每个
对单个
加载数据到 - 在单个PE上使用微内核
处理 的数据(中间结果存储在 中) - 最终将结果从
写回到
(2)
各个
根据以上GEMM表示形式,如果使用微内核
共有t1 * t2 个流水线任务,PE个数为
(3)
由于在运行时才会得到 t1 t2 t3,因而只考虑单个流水线任务即可
定义性能模型函数
微内核聚合
聚合模式
在这个阶段,MIkpoly将
Mikpoly将操作符GEMM的输出分为7块,具体如下图(a)所示,并依据这7块区域的不同组合方式设置出了9种不同的聚合模式。(通过大量的负载评估实验中得到)
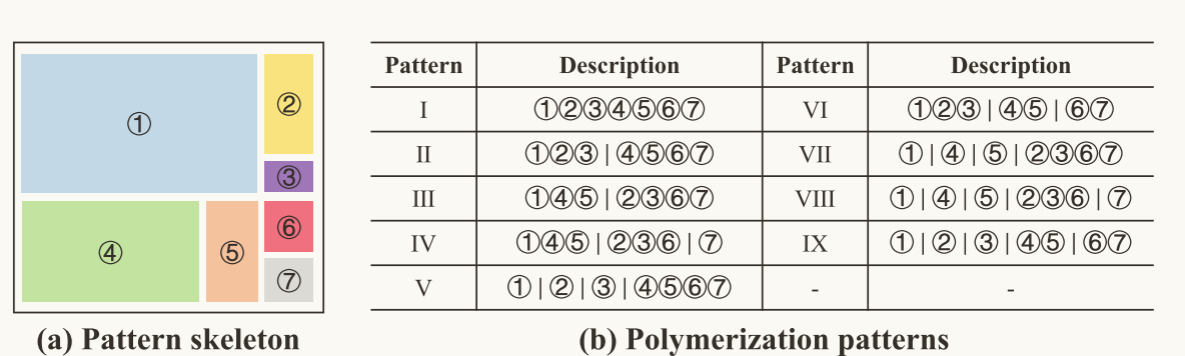
聚合策略
使用在离线评估性能在前
填充技术的原理如下图所示:

聚合成本模型
该模型考虑因素如下:
- 微内核生成时的性能模型
- 程序在实际执行过程中的并发性
采用的成本模型如下:
$$
\text{Cost}(S, H) = \sum_{(R_i, \tilde{K}i) \in S} f{\text{wave}}(R_i, \tilde{K}i, H) \times f{\text{pipe}}(R_i, \tilde{K}_i, H)
$$
$$
f_{\text{wave}}(R_i, \tilde{K}i, H) = \left\lceil \frac{f{\text{parallel}}(R_i, \tilde{K}i)}{|P{\text{multi}}|} \right\rceil
$$
$$
f_{\text{pipe}}(R_i, \tilde{K}i, H) = g{\text{predict}} \left( f_{\text{num}}(R_i, \tilde{K}_i), \tilde{K}_i, H \right)
$$
其中
$f_{\text{num}}(R_i, \tilde{K}i)
MIkpoly完整算法实现

离线生成阶段(Offline Generation):
- 在这个阶段,优化后的微核
是通过微核模板 使用 TVM 自动调度器生成的。
动态多态化阶段(On-the-Fly Polymerization):
- 当运行时知道某个动态形状时,MikPoly 会尝试应用预定义的模式基于一个两阶段的模板 Q。
- MtkPoly 利用启发式方法来探索多态化策略,并估算代价。
- 如果
的成本超过当前最佳策略的成本,那么相关的策略将会被跳过,从而显著缩小搜索空间并减少运行时的开销。
最终结果:
- MtkPoly 基于最佳的多态化策略,构建了一个优化的张量程序
。
4 Implementation
本节对不同的加速器平台的实现细节进行阐述。
GPU 平台
- 自动调度器和模板:
- 对于 GPU,MtkPoly 使用 TVM 自动调度器结合 CUTLASS 模板,生成固定大小的参数化微核。生成的微核被编译成二进制文件,并保持恒定的形状大小,张量的起始地址和循环迭代次数在运行时作为参数动态确定。
- 动态多态化:
- 在运行时,MtkPoly 基于输入形状选择合适的多态化策略,并实例化对应的微核。对于 GPU,采用了模式 I 和 II,以保持性能与运行时开销之间的最佳平衡。线程块通过 GPU 硬件调度器动态分配给多处理器(SM),避免静态分配。
- 性能优化:
- 由于硬件的高效动态调度能力,GPU 上不需要静态分配线程资源,重点在于减少运行时的开销。因此,MtkPoly 仅使用少量预定义的模式(模式 I 和 II),以优化性能和运行时效率。张量地址偏移等信息在运行时传递给微核,并通过标量赋值,确保最小化的开销。
NPU 平台
- 手动模板和分配:
- 对于 NPU,MtkPoly 使用手动模板生成固定大小的参数化微核。与 GPU 类似,生成的微核同样编译为二进制文件,并保持恒定的形状大小,同时将张量的起始地址和循环迭代次数作为运行时参数。
- 动态多态化:
- 在 NPU 上,MtkPoly 提供了更多的模式选择(模式 I-IX),并使用最大-最小静态分配算法将任务并行化分配到多个计算核心(如 DaVinci Cores)。这些模式为微核在多个处理单元之间的分配提供了灵活性和更高的并行性能。
- 性能优化:
- 在 NPU 平台上,由于更注重并行化执行的性能,手动分配的微核使用最大-最小静态分配算法来优化不同核心之间的任务负载分布,以提升整体性能。与 GPU 不同,NPU 的并行化任务需要手动调度和分配,因此 NPU 使用了更多的多态化模式来适应不同的任务。
5 Evaluation
Mikpoly的目标:能够有效优化加速器上的动态张量算子和神经网络,表现优于现有的水平
模型评估主要聚焦于两个问题:
- 是否能够优化动态张量算子和神经网络
- 提出的成本模型是否能够有效地支持微内核聚合
实验环境
硬件平台:
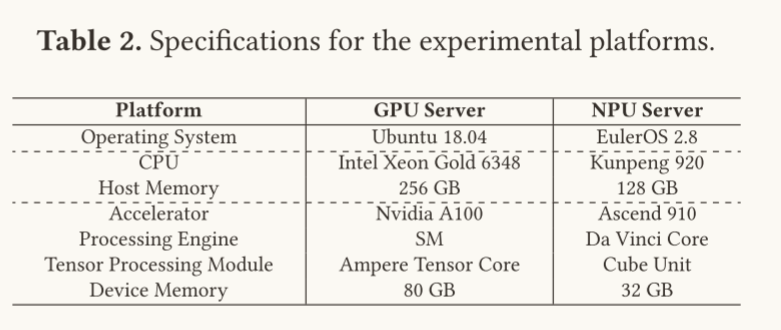
软件环境:
| 平台 | 软件环境 | 性能评估工具 |
|---|---|---|
| GPU | CUTLASS、CUDA toolkit(with cuBLAS and cuDNN libraries) | Pytorch for CNN models and TuroTransformers for languanges models |
| NPU | CANN SDK | MindSpore |
软件解释:
- cuBLAS and cuDNN在GPU上提供了GEMM和卷积运算的标准基础实现
- CUTLASS在GPU上提供了GEMM的模板化实现,用于加速GEMM和卷积运算操作
备注:
- 对上述的库中实现卷积操作的操作使用GEMM算子实现
- 进行实验的预热操作,提前对程序运行20次
基准测试
针对GEMM算子和卷积算子进行测试,
测试样例选择
GEMM算子:
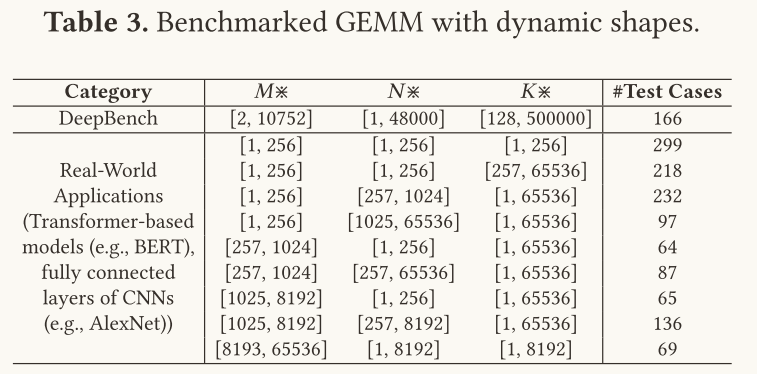
测试样例分别来自百度的基准测试工具DeepBench,和真实世界中出现的GEMM算子的动态形状范围示例(包括基于Transformer的模型和基于CNN的模型)
卷积算子:

测试样例取自具有代表性的四类CNN网络模型
测试过程
将基础库(cuBLAS、cuDNN、CANN)中的标准GEMM算子和卷积算子替换成Mikpoly优化后的算子,对四种语言模型和四种CNN网络进行推理性能的测试
性能结果
对动态形状算子的优化效果
MIKPOLY vs GPU libraries
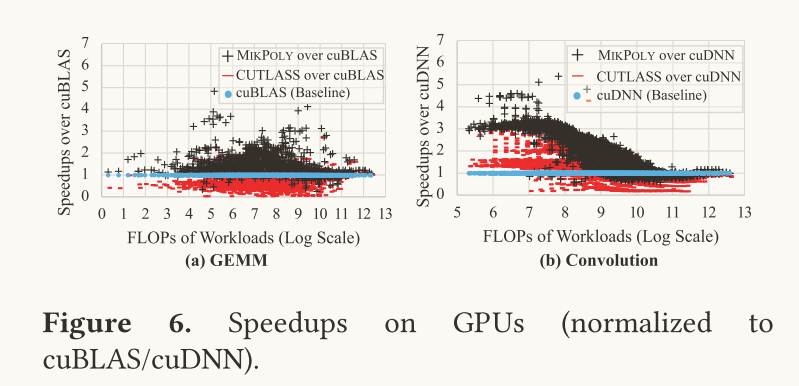
该表解读:
- 定性来看:对于GEMM和卷积算子而言,Mikpoly、CUTLASS、cuBLAS(Mikpoly、CUTLASS、cuDNN)中效果最好的为Mikpoly
- 定量来看:Mikpoly
- 与cuBLAS相比,平均GEMM加速比为1.47倍(最大为4.82倍)
- 与cuDNN相比,平均卷积加速比为1.98倍(最大为5.38倍)
- 与CUTLASS相比,平均GEMM加速比和卷积加速比分别为3.02倍和1.72倍
MIKPOLY vs NPU libraries
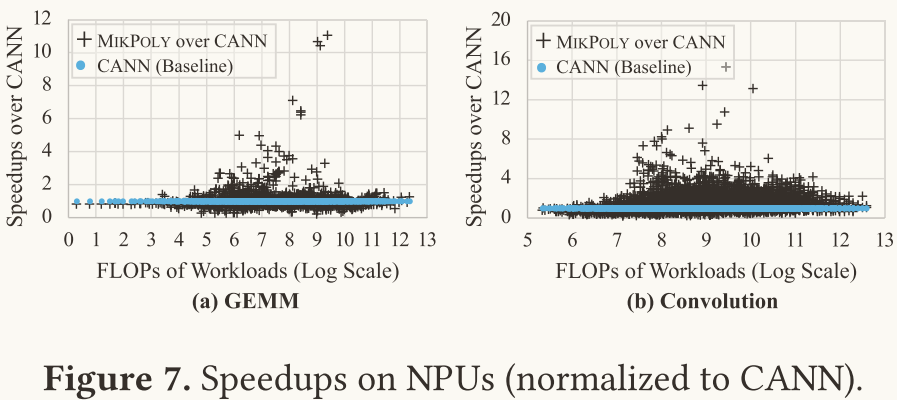
该表解读:
相较于CANN这个NPU厂商提供的自建库,Mikpoly的效果更好。其中GEMM和卷积的加速比分别为 1.10和1.41倍
对动态模型推理的优化效果
MiKPOLY对模型推理的延迟 = Mikpoly成本模型的计算时间(
GPU上进行模型推理
(四种语言模型和四种CNN网络)
测试主体:
- Mikpoly
- CUTLASS
- cuBLAS / cuDNN(其效果作为基准线)
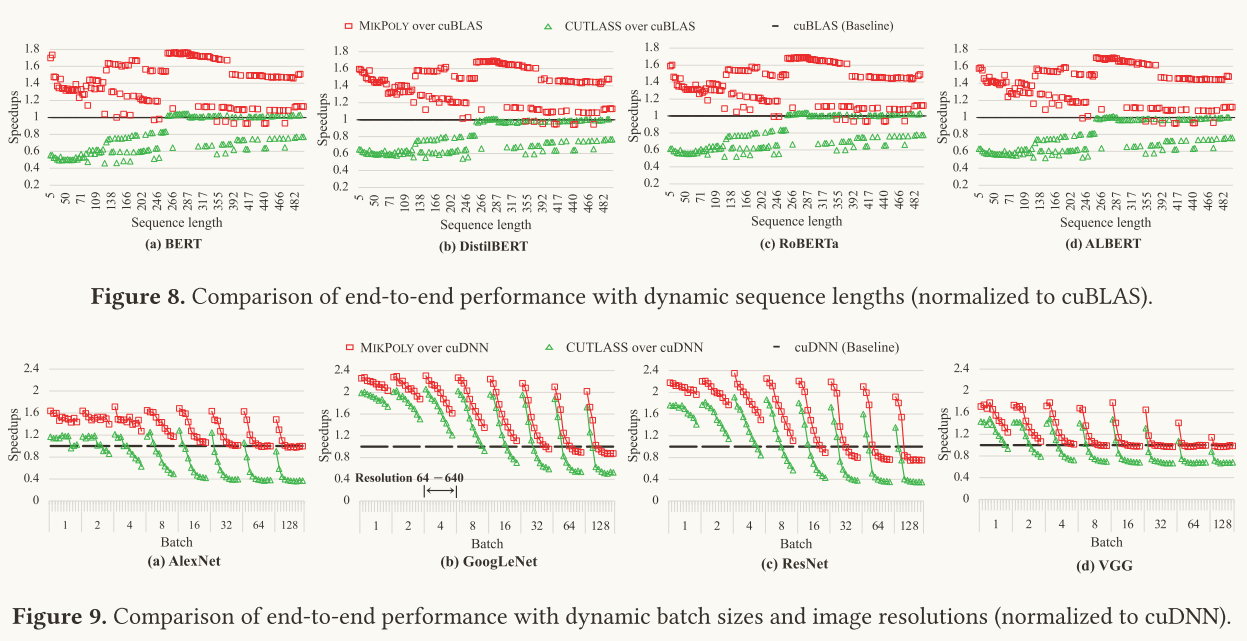
对上述两表的解读:
定性看:Mikpoly的效果在三者中是最好的;
定量看:Mikpoly相对于cuBLAS / cuDNN对四种语言模型的加速比分别为1.39、1.38、1.36、1.37
Mikpoly相对于cuBLAS / cuDNN对四种CNN模型的加速比分别为1.34、1.69、1.52、1.22
NPU上进行模型推理
和CANN相比,Mikpoly在四种CNN网络中的平均加速比为1.30、1.19、1.32、1.38
Mikpoly和现有技术对比
所比较对象:
Mikpoly
现有的动态形状张量编译器 DietCode、Nimble
厂商自建库CUTLASS
测试样例取自前文使用GEMM算子的1433个测试案例
测试结果如下表所示:
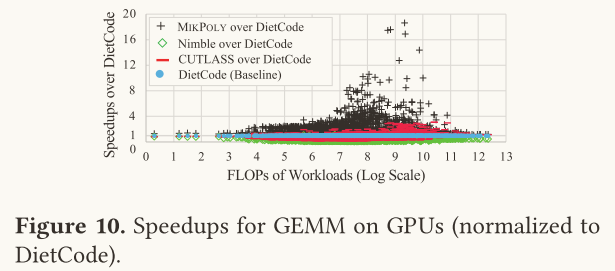
根据该表,Mikpoly相比于DietCode、Nimble、CUTLASS的加速比分别为2.94、7.54、3.59
深入测试:测试四种语言模型的模型推理性能,实验结果如下表所示:

通过该表得到Mikpoly相较于剩余三种工具中性能最优的DietCode的加速比平均为1.55
根据实验得到的差异进行分析:因为动态编译器预先定义好了动态形状的变化范围,因为当实际的形状超出了它所定义的范围时,程序会因为越界错误或者资源不可用导致无效的错误。
下面使用实验验证分析的正确性:
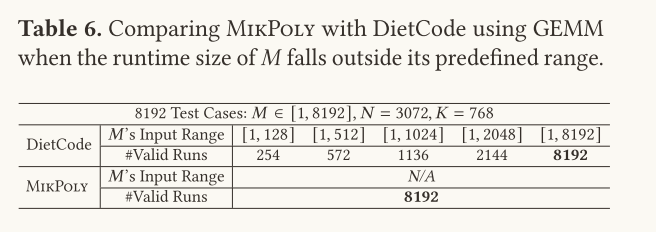
根据上表,当预先设定DietCode输入范围为128、512、1024、2048、8192时,在整个的8192个测试样例中,其有效执行次数始终没有Mikpoly效果好,另外假设测试样例的范围就是DietCode的预先设定值时,它的运行效果仍旧没有Mikpoly效果好,这一点可通过下表得到。
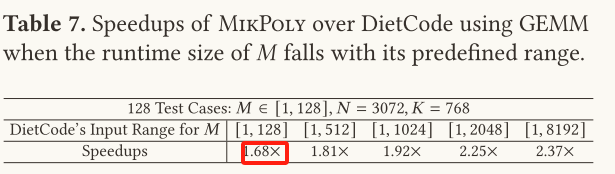
将Mikpoly应用到大语言模型LLM
在这部分文章选用LLM的一个版本——Llama2-13b
对比主体:
- Mikpoly
- Faster Transformer(专门针对英伟达GPU的模型加速推理工具)
测试结果:
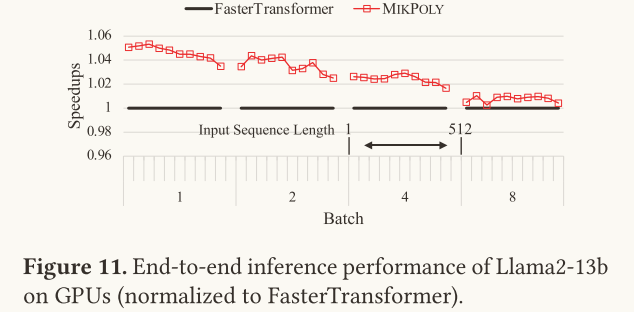
通过上表可以得到:在不同的batch size(1、2、4、8)和不同的输入序列长度下,Mikpoly相较于
Faster Transformer的平均加速比为1.05 1.04 1.02 1.01
性能分析
该部分对GEMM算子在GPU上的完整性能进行分析
在线聚合开销
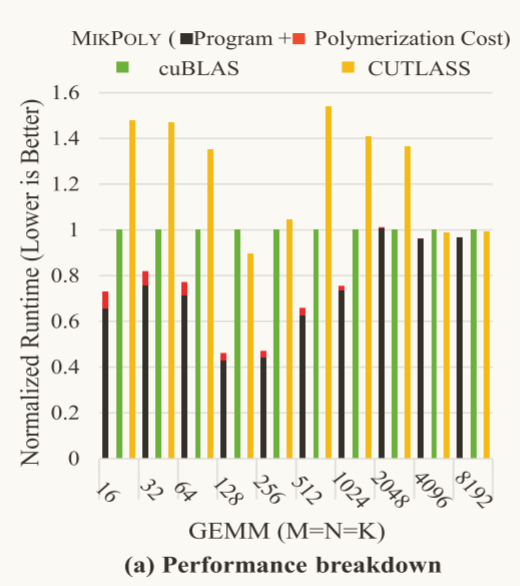
通过该表可知,Mikpoly在这三种GEMM实现工具中的总体运行时间是最短的(以cuBLAS为基线)
另外,Mikpoly中的聚合成本(红色部分)占其总体运行成本的一小部分,并且由于高效的成本模型,这部分成本随着形状的增大而减少
成本模型有效性
为了证明成本模型的有效性,提出了三种Mikpoly的变体:
- Mikpoly-ORACLE 在动态聚合阶段采用穷举搜索,最终只计算优化后的程序的运行时间,不考虑动态聚合时的时间成本
- Mikpoly-WAVE 尽可能减少并行度,因而容易产生大尺寸的微内核
- Mikpoly-PIPE 最大化单个流水线任务的性能,容易产生小尺寸的微内核
对以上三种变体,再加上Mikpoly和CUTLASS一共五个测试主体(以Mikpoly-ORACLE 为基线),测试得到如下结果:
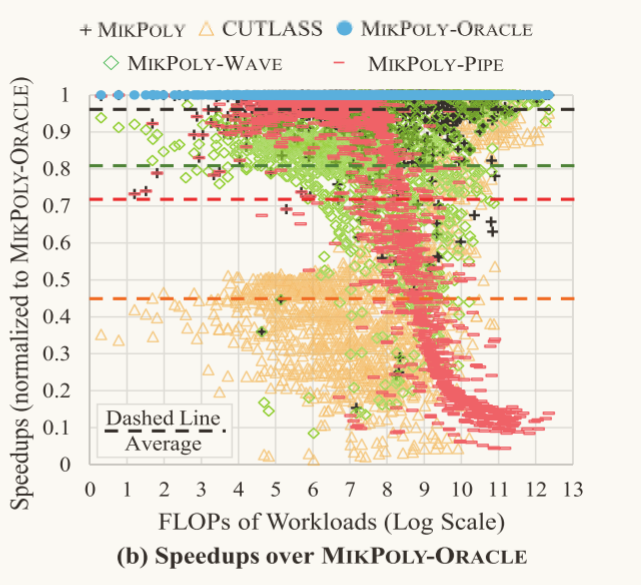
实验结果:
相较于Mikpoly-ORACLE,Mikpoly、Mikpoly-WAVE、Mikpoly-PIPE的加速比分别为0.96、0.81、0.72
结果分析:
Mikpoly考虑了减少并行度和最大化单个流水线任务的性能,因而在Mikpoly、Mikpoly-WAVE、Mikpoly-PIPE中性能最好。
虽然Mikpoly-ORACLE的运行时性能最好,但是在线聚合阶段由于其采用了穷举搜索的方法,因而根据给定的动态形状到最终产生合适的聚合策略的时间长达1.6秒,而Mikpoly则只需要2微秒;同时从最终的运行时间看,Mikpoly-ORACLE只计算运行时的时间和Mikpoly聚合时间加上优化后程序运行时间大致相同,这说明了成本模型的有效性
超参数分析
本部分对前文在离线阶段微内核生成时涉及到的三个超参数进行探讨
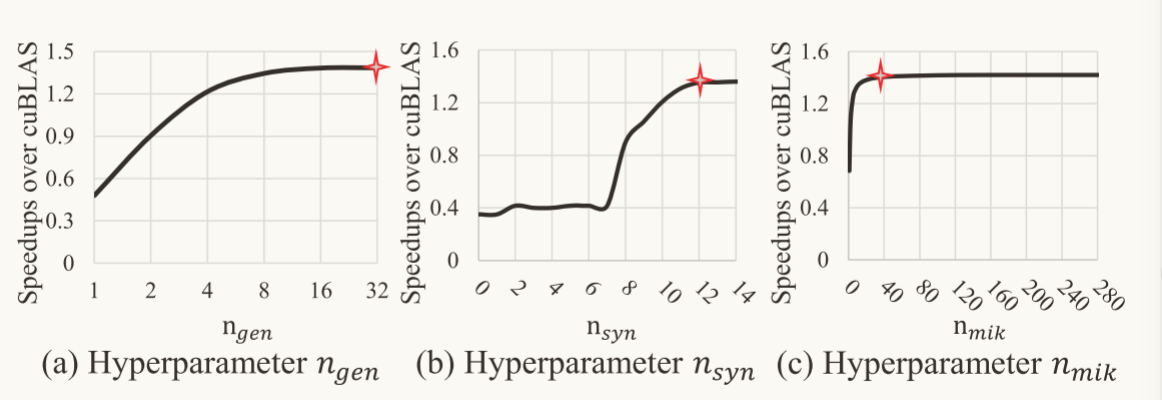
通过该表可以得到,随着三个超参数的增加,Mikpoly相对于cuBLAS的加速比逐渐上升,并最终达到饱和点,根据该图得到三个超参数的最终设置的值
6 Case Studies
在这部分探讨微内核聚合有效性的根本原因——提高了硬件利用率、缓解了负载不均衡的问题
该部分考虑动态形状(M N K) = (4096,1024,4096),使用以下三种微内核组合对该算子进行优化:
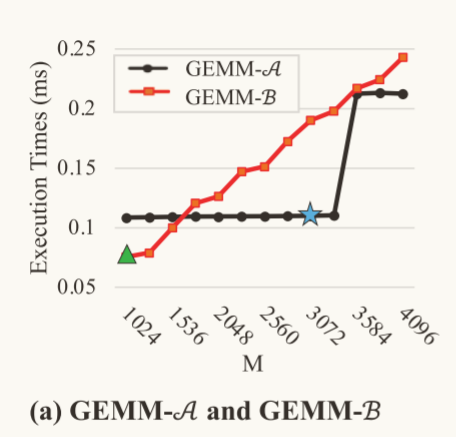
通过上图可以得到,
在GPU上分别对这两种微内核组合进行测试,使用GPU的性能分析工具测试相关的测试指标,得到的结果如下:
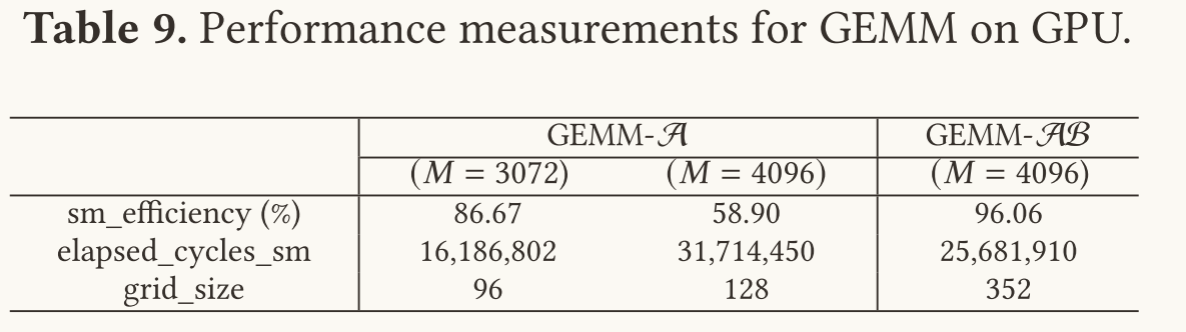
性能指标解释:
sm_efficiency%:一个SM(流式处理器)上至少有一个wrap(线程组)处于活动状态的时间百分比
elapsed_cycles_sm:每个SM上的始终周期数
grid_size:为GEMM任务分配的线程块的数量
通过该表可知,在采用微内核聚合之后,sm的利用率上升,并且单个sm的时钟周期数目降低(任务完成时间减少了),这样就提高了硬件的利用率,最终的效果自然也就更好了
除了使用性能评估工具对相关指标进行测试外,文章还对两种组合优化后的程序在实际硬件中的运行轨迹进行了建模,使用理论计算得出微内核聚合对负载不均衡的缓解问题。
理论计算过程如下:
使用GPU型号为A100,它含有108个SM,每个SM最多容纳64个wrap;
在实际的运行过程中,两个kernel(
、 )对SM的占用率只有1 / 8,为8 wrap / SM; 108 * 8 = 864,即每个波次该GPU只能处理864个wrap;
1 | 对于GEMM-A =(256,128,32): |
1 | 对于GEMM-AB: |
对上述的计算过程进行绘图,得到下图:
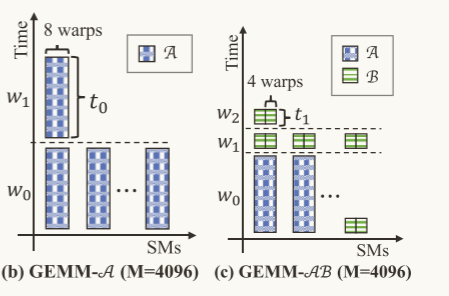
根据该图,可以得到两个组合的执行时间分别为 (2 * Ta) 和 (Ta + 2 * Tb)
其中Ta、Tb分别表示两个内核组合执行单个流水线任务的时间。
在Ta > 2 * Tb时,微内核聚合相对于单个微内核的效果为(2 * Ta) / (Ta + 2 * Tb) 倍。
7 Discussion
通用性
在GPU/NPU上对GEMM/卷积算子和语言模型和CNN网络的加速效果好
适用性
- 对输入形状在较大范围内频繁变化时的操作符表现良好
- 在编译时已知某些输入形状的范围时,可通过更加合适的微内核集合的生成来细化成本模型,最终实现更好的优化来增强性能
限制
- 计划探索MikPoly与图级优化技术的结合,例如算子融合,以进一步增强动态形状场景中图级的性能
- 当前的实现使用基于GEMM的卷积方法,研究其他卷积实现有潜在的好处,例如Winograd,它可能会提供额外的性能改进